
Parallel Fractal Image Generation
Performance Analysis
Our next step is analyze to analyze the performance of the algorithm we just developed. We want to see how much time we actually save by computing the parts of the image in parallel, and we need to check if the synchronization mechanism introduces any overhead.
In order to see how the execution time changes with the problem size, we run the program with a maximum iteration count of N = 5,000, N = 50,000 and N = 500,000.
To get good measurements without too much influence of fluctuating system performance (e.g. background processes, other users' activity), we calculate the image of the whole Mandelbrot set with 160 x 120 pixels and run the program three times for each choice of N, averaging the results. After completing all the test runs, we end up with the following (averaged) timings:
| average TP,N |
P = 1 (serial) |
P = 2 |
P = 4 |
P = 6 |
| N = 5,000 |
1.43199333 s |
0.48863167 s |
0.25034200 s |
0.17215833 s |
| N = 50,000 |
14.18023330 s |
4.67098667 s |
2.36133667 s |
1.58265667 s |
| N = 500,000 |
141.93433300 s |
46.43553330 s |
23.48320000 s |
15.71240000 s |
Table 4: Average execution walltime
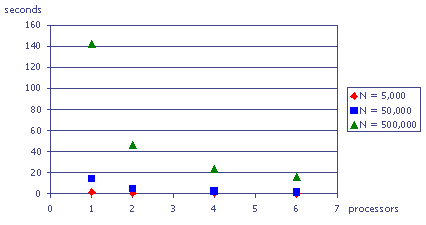
Figure 12: Execution walltime chart
Table 4 shows that the execution time grows almost proportionally with the maximum number of iterations. This makes sense since the number of points computed remains the same, but the time to compute the points inside the set grows with the number of iterations. Since the time required for most points outside the set stays the same no matter how high the iteration maximum, the relation can not be exactly proportional.
We are mainly interested in the performance gain that can be achieved when using a parallel algorithm on a certain number of processors as opposed to a serial algorithm on one processor. From Figure 12, we can deduce that with an increasing number of processors, the execution time decreases overproportionally � for example, we would expect that by doubling the number of processors, we can cut the execution time in half, but the actual execution time is even less than that. To examine this effect, we compute the speedups, defined as
![S[P,N] = T[1,N] / T[P,N]](image028.gif)
where TP,N is the overall execution time when running on P processors with an iteration maximum of N.
| SP,N |
P = 2 |
P = 4 |
P = 6 |
| N = 5,000 |
2,93061915 |
5,72014816 |
8,31788581 |
| N = 50,000 |
3,03581113 |
6,00517219 |
8,95976592 |
| N = 500,000 |
3,05658884 |
6,04407973 |
9,03326882 |
Table 5: Speedups
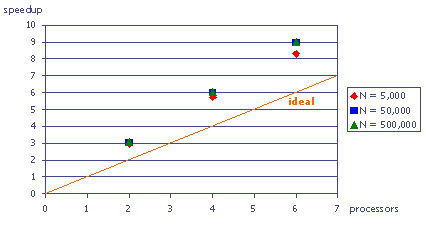
Figure 13: Speedup chart
Surprisingly, the achieved speedups are even higher than the "ideal" linear speedup, although the parallel program does even more work than the serial program, since it has to communicate in order to synchronize the output. We can rule out an erroneous measurement since all test runs were performed three times, and the timings were within remarkably close range. One might imagine some external influence (like a background process or another user's job) slowing the serial program down, but this would only have yielded a deviation in one measurement, but not in all nine test runs of the serial program. We can therefore assume that the timings must be correct.
The overproportional speedup can be explained when we look more closely at the differences between the serial and the parallel algorithm: In the serial algorithm, we compute a point, output it, compute the next point, output it, and so on - the whole algorithm is completely serial (Figure 14):
| Node 0: |
| compute |
output |
compute |
output |
compute |
output |
compute |
output |
compute |
... |
|
Figure 14: Operations in serial execution
In the parallel algorithm, we obviously have several nodes computing points in parallel. But in addition to this, we have a second layer of parallelism introduced by the non-blocking communication because the output of a node (sending a line to the master) is performed in the background while the computation continues:
| Node 0: |
| compute |
compute |
compute |
compute |
compute |
compute |
compute |
compute |
compute |
... |
| |
output |
|
output |
|
|
| Node 1: |
| compute |
compute |
compute |
compute |
compute |
compute |
compute |
compute |
compute |
... |
| |
output |
|
output |
|
|
| Node 2: |
| compute |
compute |
compute |
compute |
compute |
compute |
compute |
compute |
compute |
... |
| |
output |
|
output |
|
|
Figure 15: Operations in two-level parallel execution
It might be argued that the parallel execution of computation and output is an illusion created by the operating system's multi-tasking, since the output process running in the background takes CPU time slices away from the computation process. However, this is not really the case: The transmission of data is an I/O operation that does not involve the CPU anymore after being initiated.
The parallel execution of computation and output in every node is therefore real and a subtle, but deciding factor in the overproportional speedup that we observe.
< Polling Synchronization | Conclusion >

